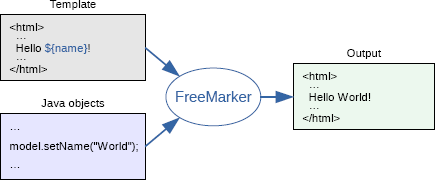
#!/usr/bin/env python
# coding=utf-8
import os
import time
import threading, datetime, hashlib
import oss2
import phpserialize
from multiprocessing import Pool, cpu_count
import requests
import pymysql
from bs4 import BeautifulSoup
now = datetime.datetime.now()
HEADERS = {
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'Referer': "http://www.mmjpg.com"
}
DIR_PATH = r"/var/www/python/mmjpg" # 下载图片保存路径
# 阿里云主账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM账号进行API访问或日常运维,请登录 https://ram.console.aliyun.com 创建RAM账号。
auth = oss2.Auth('ak', 'sk')
# Endpoint以杭州为例,其它Region请按实际情况填写。
bucket = oss2.Bucket(auth, 'http://oss-cn-shenzhen-internal.aliyuncs.com', 'bucket')
def save_pic(pic_src, pic_cnt, folder_name):
"""
将图片下载到本地文件夹
"""
try:
img = requests.get(pic_src, headers=HEADERS, timeout=10)
img_name = "pic_cnt_{}.jpg".format(pic_cnt + 1)
with open(img_name, 'ab') as f:
f.write(img.content)
bucket.put_object_from_file('uploads/' + now.strftime('%Y') + '/' + now.strftime('%m') + '/' + folder_name +
img_name,
DIR_PATH + '/' + folder_name + '/' + img_name)
print(img_name)
#阿里云oss访问地址
return 'http://123.oss-cn-shenzhen.aliyuncs.com/uploads/' + now.strftime('%Y') \
+ '/' + now.strftime('%m') \
+ '/' + folder_name + img_name
except Exception as e:
print(e)
def make_dir(folder_name):
"""
新建套图文件夹并切换到该目录下
"""
path = os.path.join(DIR_PATH, folder_name)
# 如果目录已经存在就不用再次爬取了,去重,提高效率。存在返回 False,否则反之
if not os.path.exists(path):
os.makedirs(path)
print(path)
os.chdir(path)
return True
print("Folder has existed!")
return False
def delete_empty_dir(save_dir):
"""
如果程序半路中断的话,可能存在已经新建好文件夹但是仍没有下载的图片的
情况但此时文件夹已经存在所以会忽略该套图的下载,此时要删除空文件夹
"""
if os.path.exists(save_dir):
if os.path.isdir(save_dir):
for d in os.listdir(save_dir):
path = os.path.join(save_dir, d) # 组装下一级地址
if os.path.isdir(path):
delete_empty_dir(path) # 递归删除空文件夹
if not os.listdir(save_dir):
os.rmdir(save_dir)
print("remove the empty dir: {}".format(save_dir))
else:
print("Please start your performance!") # 请开始你的表演
lock = threading.Lock() # 全局资源锁
def urls_crawler(url):
"""
爬虫入口,主要爬取操作
"""
try:
r = requests.get(url, headers=HEADERS, timeout=10).text
# 套图名,也作为文件夹名
folder_name = BeautifulSoup(r, 'lxml').find(
'h2').text.encode('ISO-8859-1').decode('utf-8')
post_tags = []
tags = BeautifulSoup(r, 'lxml').find(
'div', class_='tags').find_all('a')
for tag in tags:
post_tags.append('"'+tag.text.encode('ISO-8859-1').decode('utf-8')+'"')
path_name = hashlib.md5(folder_name.encode('utf-8')).hexdigest()[8:-8]
with lock:
if make_dir(path_name):
# 套图张数
max_count = BeautifulSoup(r, 'lxml').find(
'div', class_='page').find_all('a')[-2].get_text()
# 套图页面
page_urls = [url + "/" + str(i) for i in
range(1, int(max_count) + 1)]
# 图片地址
img_urls = []
for index, page_url in enumerate(page_urls):
result = requests.get(
page_url, headers=HEADERS, timeout=10).text
# 最后一张图片没有a标签直接就是img所以分开解析
if index + 1 < len(page_urls):
img_url = BeautifulSoup(result, 'lxml').find(
'div', class_='content').find('a').img['src']
img_urls.append(img_url)
else:
img_url = BeautifulSoup(result, 'lxml').find(
'div', class_='content').find('img')['src']
img_urls.append(img_url)
oss_img_urls = [];
for cnt, url in enumerate(img_urls):
oss_img_urls.append(save_pic(url, cnt, path_name))
# 打开数据库连接
db = pymysql.connect("127.0.0.1", "root", "123456", "wordpress")
# 使用cursor()方法获取操作游标
cursor = db.cursor()
now_time = now.strftime('%Y-%m-%d %H:%M:%S')
try:
# SQL 插入语句
sql = """INSERT INTO `wordpress`.`wdposts`
(`post_author`, `post_date`, `post_date_gmt`, `post_content`,
`post_title`, `post_excerpt`, `post_status`, `comment_status`,
`ping_status`, `post_password`, `post_name`, `to_ping`, `pinged`,
`post_modified`, `post_modified_gmt`, `post_content_filtered`,
`post_parent`, `guid`, `menu_order`, `post_type`, `post_mime_type`,
`comment_count`) VALUES
(1, '""" + now_time + """', '""" + now_time + """', '[vc_row][vc_column][vc_column_text] <h2>""" + folder_name + """</h2> [/vc_column_text][/vc_column][/vc_row][vc_row full_width="stretch_row_content" css=".vc_custom_1444807993418{padding-right: 35px !important;padding-left: 35px !important;}"][vc_column][ultimate_spacer height="60"][/vc_column][/vc_row][vc_row full_width="stretch_row_content" css=".vc_custom_1444987361109{padding-right: 35px !important;padding-left: 35px !important;}"][vc_column][royal_portfolio portfolio_display_filters="yes" portfolio_display_title="yes" portfolio_display_testimonial="yes" portfolio_posts_number="15" portfolio_columns_rate="+1" portfolio_gutter_horz="17" portfolio_gutter_vert="17" portfolio_stretch_container="yes"][/vc_column][/vc_row]',
'""" + folder_name + """', '', 'publish', 'open', 'closed', '', '""" + path_name + """', '', '',
'""" + now_time + """', '""" + now_time + """', '', 0,
'http://meizg.louislivi.com/?post=""" + path_name + """', 0,
'post', '', 0)"""
# 执行sql语句
cursor.execute(sql)
db.commit()
# 提交到数据库执行
post_id = str(cursor.lastrowid)
sql = "select term_taxonomy_id from wdterms right join wdterm_taxonomy on wdterm_taxonomy.term_id=wdterms.term_id where name in (" + (",".join(str(i) for i in post_tags)) + ")"
cursor.execute(sql)
result = cursor.fetchall()
sql = "insert into wdterm_relationships(object_id,term_taxonomy_id) VALUES (" + post_id + ",43),(" + post_id + ",30),(" + post_id + ",227941),"
term_ides = []
for tag_id in result:
sql += "(" + post_id + "," + str(tag_id[0]) + "),"
term_ides.append(tag_id[0])
cursor.execute(sql[0:-1])
db.commit()
sql = "update wdterm_taxonomy set count=count+1 where term_id in (" + (",".join(str(i) for i in term_ides)) + ")"
cursor.execute(sql)
db.commit()
sql = """INSERT
INTO
wordpress.wdposts(post_author, post_date, post_date_gmt, post_content, post_title, post_excerpt,
post_status, comment_status, ping_status, post_password, post_name, to_ping, pinged,
post_modified, post_modified_gmt, post_content_filtered, post_parent, guid,
menu_order, post_type, post_mime_type, comment_count)
VALUES"""
for cnt, url in enumerate(oss_img_urls):
sql += """(1, '""" + now_time + """', '""" + now_time + """', '""" + folder_name + str(cnt) + """', '""" + folder_name + str(cnt) + """', '""" + folder_name + str(cnt) + """', 'inherit', 'open','closed',
'', '""" + folder_name + str(
cnt) + """', '', '', '""" + now_time + """', '""" + now_time + """', '', """ + post_id + """,
'""" + url + """', 0, 'attachment', 'image/jpeg',
0),"""
cursor.execute(sql[0:-1])
db.commit()
sql = """select ID from wdposts where post_parent=""" + post_id + """ order by id asc;"""
cursor.execute(sql)
result = cursor.fetchall()
img_post_ides = []
for i in range(len(result)):
img_post_ides.append(result[i][0])
sql = """insert into wdpostmeta(post_id,meta_key,meta_value) values """
pic_cnt = 1
for img_post_id, img_url in zip(img_post_ides, oss_img_urls):
img_file_name = path_name + 'pic_cnt_' + str(pic_cnt)
img_name = img_file_name + '.jpg'
meta_list = {
"width": "800",
"height": "1200",
"hwstring_small": "height='96' width='64'",
"file": now.strftime('%Y') + '/' + now.strftime('%m') + '/' + img_name,
"sizes": {
"thumbnail":
{
"file": img_file_name + "-150x150.jpg",
"width": "150",
"height": "150",
"mime-type": "image/jpeg",
},
"medium": {
"file": img_file_name + "-200x300.jpg",
"width": "200",
"height": "300",
"mime-type": "image/jpeg",
},
"medium_large": {
"file": img_file_name + "-768x1152.jpg",
"width": "768",
"height": "1152",
"mime-type": "image/jpeg",
},
"large": {
"file": img_file_name + "-683x1024.jpg",
"width": "683",
"height": "1024",
"mime-type": "image/jpeg",
},
"royal-similar-items": {
"file": img_file_name + "-350x350.jpg",
"width": "350",
"height": "350",
"mime-type": "image/jpeg",
},
"royal-search-results": {
"file": img_file_name + "-150x150.jpg",
"width": "150",
"height": "150",
"mime-type": "image/jpeg",
},
"royal-blog-post": {
"file": img_file_name + "-750x450.jpg",
"width": "750",
"height": "450",
"mime-type": "image/jpeg",
},
"royal-portfolio-post": {
"file": img_file_name + "-500x340.jpg",
"width": "500",
"height": "340",
"mime-type": "image/jpeg",
},
"post-thumbnail": {
"file": img_file_name + "-800x450.jpg",
"width": "800",
"height": "450",
"mime-type": "image/jpeg",
},
"detail": {
"file": img_file_name + "-150x150.jpg",
"width": "150",
"height": "150",
"mime-type": "image/jpeg",
}
},
"image_meta": {
"aperture": "0",
"credit": "",
"camera": "",
"caption": "",
"created_timestamp": "0",
"copyright": "", "focal_length": "0",
"iso": "0",
"shutter_speed": "0",
"title": "", "orientation": "0",
"keywords": {}, }
}
meta_value = phpserialize.dumps(meta_list)
sql += """(""" + str(img_post_id) + """,'_wp_attachment_metadata','""" + str(meta_value)[2:-1] + """'),
(""" + str(img_post_id) + """,'_wp_attached_file','/var/www/html/wp-content/uploads/""" \
+ now.strftime('%Y') + '/' + now.strftime('%m') + '/' + img_name \
+ """'),"""
pic_cnt += 1
cursor.execute(sql[0:-1])
db.commit()
sql = """insert into wdpostmeta(post_id,meta_key,meta_value) values (""" + post_id + """,'_thumbnail_id','""" + str(
img_post_ides[-1]) + """'),
(""" + post_id + """,'_vc_post_settings','a:1:{s:10:"vc_grid_id";a:0:{}}'), (""" + post_id + """,'slide_template','default'),
(""" + post_id + """,'rf_metro_post_width','1x'), (""" + post_id + """,'rf_exc_featured_img','""" + str(
img_post_ides[1]) + """'), (""" + post_id + """,'rf_audio_type','embed'),
(""" + post_id + """,'rf_audio_embed',''), (""" + post_id + """,'rf_audio_self_mp3',''), (""" + post_id + """,'rf_audio_self_ogg',''),
(""" + post_id + """,'rf_video_type','embed'), (""" + post_id + """,'rf_video_embed',''), (""" + post_id + """,'rf_video_self_mp4',''),
(""" + post_id + """,'rf_video_self_ogv',''), (""" + post_id + """,'rf_gallery_type','stacked'), (""" + post_id + """,'rf_gallery_img_ids','""" + (
",".join(str(i) for i in img_post_ides)) + """'),
(""" + post_id + """,'rf_gallery_imgs_src','""" + (",".join(str(i) for i in oss_img_urls)) + """'),
(""" + post_id + """,'rf_back_link','""" + str(
int(post_id) - 1) + """'), (""" + post_id + """,'rf_project_desc_title','""" + folder_name + """'), (""" + post_id + """,'rf_project_description','""" + folder_name + """'),
(""" + post_id + """,'rf_project_details_title',''), (""" + post_id + """,'rf_project_client','meizg.com'),
(""" + post_id + """,'rf_project_url','http://meizg.louislivi.com/?post=""" + path_name + """'),
(""" + post_id + """,'rf_testimonial_author','meizg.com'), (""" + post_id + """,'rf_testimonial_content',''), (""" + post_id + """,'rf_revslider_shortcode',''),
(""" + post_id + """,'rf_revslider_select','none'), (""" + post_id + """,'rf_project_info_sticky','no'), (""" + post_id + """,'second_featured_img_id','""" + str(
img_post_ides[-2]) + """'),
(""" + post_id + """,'_wpb_vc_js_status','true'),
(""" + post_id + """,'_wpb_shortcodes_custom_css','.vc_custom_1444807993418{padding-right: 35px !important;padding-left: 35px !important;}.vc_custom_1444987361109{padding-right: 35px !important;padding-left: 35px !important;}'),
(""" + post_id + """,'rf_enable_project_info','yes'), (""" + post_id + """,'_edit_lock','1535778316:1'), (""" + post_id + """,'_edit_last','1'),
(""" + post_id + """,'rf_project_info_offset','0'), (""" + post_id + """,'rf_project_ext_url',''), (""" + post_id + """,'_wp_trash_meta_status','publish'),
(""" + post_id + """,'_wp_trash_meta_time','1535773952'), (""" + post_id + """,'_wp_desired_post_slug','gallery-slideshow-3');
"""
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
except:
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
except Exception as e:
print(e)
if __name__ == "__main__":
#today = datetime.date.today()
#today_time = int(time.mktime(today.timetuple()))
#cnt_num = int((today_time - 28800 - 1535644800)/86400+1459)
urls = ['http://mmjpg.com/mm/{cnt}'.format(cnt=cnt)
# 1459
for cnt in range(1, 1459)]
#urls = ['http://mmjpg.com/mm/{cnt}'.format(cnt=cnt)
# for cnt in range(cnt_num-1, cnt_num)]
pool = Pool(processes=cpu_count())
try:
delete_empty_dir(DIR_PATH)
pool.map(urls_crawler, urls)
except Exception:
time.sleep(30)
delete_empty_dir(DIR_PATH)
pool.map(urls_crawler, urls)